Tabelas hash
Contato
- Jean Paulo Martins (jeanmartins utfpr edu br)
- Sala 105, Bloco S (UTFPR - Campus Pato Branco)
Conteúdo
Introdução
Muitas aplicações precisam manipular informações sem necessariamente se preocupar na ordem em que essas informações estão armazenadas na memória. A maioria das estruturas de dados “lineares” estudadas até então, no entanto, impõe uma ordem específica aos elementos. Em uma lista, por exemplo, a inserção de um novo elemento requer que especifiquemos a posição de inserção desse elemento, o mesmo ocorre para vetores. O uso de fila de prioridades (implementadas sobre uma estrutura Heap) foi a primeira excessão a esta regra que investigamos, onde estavamos interessados sempre no mínimo elemento armazenado, mas sem nos importar necessariamente em que posição da estrutura esse elemento estava armazenado.
Nesta seção uma nova estrutura de dados será introduzida, a qual nos permitirá efetuar operações como:
- Inserção,
- Remoção, e
- Procura
de forma eficiente e sem nos preocuparmos com o posicionamento em memória dos elementos armazenados. Diferentemente das filas de prioridade, no entanto, tabelas hash permitem remoção de quaisquer elementos armazenados, não somento o mínimo/máximo. A única exigência sendo que cada um dos elementos armazenados tenha uma chave única que o identifique.
Exemplos:
- Um aluno tem como chave única que o identifica, seu RA.
- Uma pessoa tem como chave única que a identifica, seu CPF.
Endereçamento direto
Tabelas hash são uma generalização de uma forma de armazenamento com mais limitações, chamada endereçamento aberto.
Suponha que desejemos armazenar as informações sobre os funcionários de uma pequena empresa. Cada funcionário tem o seu identificador, um número que indica seu cadastro na empresa. Por se tratar de uma empresa pequena, o número de funcionários $n$ não é grande, $n\leq m$ por exemplo. É natural assumirmos que esses identificadores sejam atribuídos de forma crescente a cada novo funcionário contratado.
Neste pequeno exemplo, assumimos que tais identificadores são as chaves únicas de cada funcionário. Como o número $n$ de funcionários nunca ultrapassa $m$, um conjunto universo de chaves possíveis contendo números
é suficiente para identificar todos eles. Ou seja, cada funcionário tem um número identificador $u\in U$. Como armazenar as informações sobre tais funcionários na memória de modo a ser possível inserir, remover, e procurar de forma eficiente?
Sendo o número total de chaves $m$ de tamanho moderado, poderíamos simplesmente criar um vetor de $m$ posições.
Dada uma chave, procurar pelo funcionário associado é então trivial. Tão triviais quanto serão as operações de inserção e removação de um funcionário.
Info* search(Info* t, int chave)
return t[chave];
Info* remove(Info* t, int chave)
t[chave] = NULL;
void insert(Info* t, Info f)
t[f.chave] = f;
Neste contexto tão específico, em que sabemos que a maior chave possível $m$ é um número razoavelmente pequeno, esta é a implementação mais rápida possível. Porém, não é difícil percebermos suas limitações:
- E se as chaves $m$ forem números de 9 dígitos?
- A tabela seria gigantesca, e se o número de itens armazenados for pequeno, um grande desperdício de memória ocorreria.
- E se as chaves não forem inteiros?
- Não há como indexar a tabela com chaves não-inteiras.
Tabelas Hash
Nas situações em que endereçamento direto não se aplica, devido ao grande número de chaves possíveis, as Tabelas hash são opções interessantes.
A ideia geral de uma tabela hash é diminuir o número de chaves que precisam ser tratadas, saindo de $|U|$ para um número $m \ll |U|$ (“muito menor que”). Para isso precisamos de uma função
que mapeie cada possível chave $k\in U$ para um número $h(k)$, onde $h$ é chamada função hash.
Neste contexto, se utilizarmos $h(k)$ como índice na tabela, precisaríamos de uma tabela de tamanho $m$ ao invés de $|U|$. Como, por definição $m\ll|U|$, uma grande economia de espaço é possível. O exemplo mais simples de função hash é o uso do operador de resto (mod, %), o qual quando aplicado com o parâmetro $m$ produz um valor em ${0,\dots,m-1}$ (ver Figura).

Mas antes de finalizarmos uma implementação de tabelas hash, precisamos lidar com um importante problema. A função hash mapeia cada valor em $U$ para um valor entre $0$ e $m$, porém, como $m\ll |U|$, é inevitável que alguns valores $k_1,k_2 \in U$ tenham o mesmo valor de hash, ou seja, $h(k_1) = h(k_2)$. Isto é chamado colisão.
A menos que não nos importemos em sobrescrever elementos com memso hash, a existência de colisões nos impede uma implementação simples, em que inserimos os elementos na posição dada pela função de hash.
// Implementação inviável
void insert(Info* t, Info f)
t[h(f.chave)] = f;
Pois esse tipo de implementação somente aceitaria um dos elementos que tenham o mesmo valor de hash. Por exemplo, se houvéssemos inserido $k_1$ e posteriormente tentado inserir $k_2$, o valor $k_1$ que estava armazenado em t[h(k1)] seria sobrescrito, visto que $h(k_1)=h(k_2)$.
A seguir, analisaremos formas de tratar colisões, de modo que a tabela hash permita o armazenamento simultâneo de diversos itens com mesmo valor de hash.
Resolução de colisões por encadeamento
A resolução, ou tratamento, de colisões mais intuitiva consiste em simplesmente armazenar todos elementos cujos hash tenham colidido em uma lista encadeada. A figura abaixo ilustra essa situação
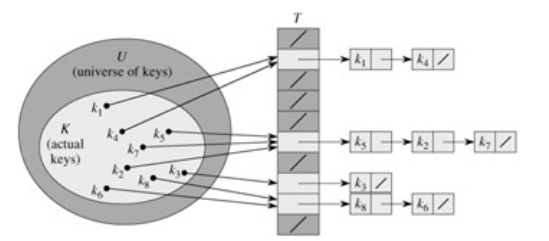
Esta forma de tratarmos colisões define como as funcionalidades devem ser implementadas: inserção, remoção, procura.
Inserção
Nesta situação, a tabela hash é simplesmente um vetor $T$, com uma lista em cada uma de suas $m$ posições (um vetor de listas: list** T). Cada uma das listas $T[i]$ armazenará elementos $x$ cujo hash seja igual ao índice $i$, i.e. $h(x)=i$. Deste modo, se o elemento $x$ ainda não existe na lista $T[i]$, basta inserí-lo.
insert(T, Info f)
i = h(f.chave)
if T[i] not contains f
insert f in t[i]
Procura
De forma análoga à inserção, podemos com certeza afirmar que se um elemento $x$, com hash $h(x)$, não é encontrado na lista $T[h(x)]$, então ele não existe na tabela hash. A função search, deste modo, é implementada em duas etapas apenas:
- calcular o hash da chave $k$ sendo procurada,
- percorrer a lista $T[h(k)]$ procurando por um item cuja chave seja igual a $k$.
search(T, k): i = h(k) if T[i] contains an element x of key k: return x else return null
Remover
A funcionalidade remover procede a partir de uma chave $k$. Similarmente a search, a primeira etapa consiste em calcular o hash da chave $k$, $h(k)$. A partir de $h(k)$, sabemos em qual das listas procurar, $T[h(k)]$. A remoção precisa então percorrer a lista $T[h(k)]$ procurando por um elemento cuja chave seja igual $k$. Caso esse elemento exista, basta removê-lo da lista, caso ele não exista, não há nada a ser feito.
remove(T, k):
i = h(k)
x = search(T[i],k)
if x not null: remove x from T[i]
Exercícios
Pair-sum [casos de teste]
Dada uma constante $K>0$ e sequência de inteiros não negativos
Verifique se existe um par $a_i$ e $a_j$, tal que $a_i + a_j = K$.
a) Implemente uma solução que utilize apenas comparações
b) Implemente uma solução com tratamento de colisões por encadeamento
c) Implemente uma solução com tratamento de colisões por endereçamento aberto.
Referências
- CORMEN, Thomas H. et al. Algoritmos: teoria e prática. Rio de Janeiro, RJ: Campus, 2002. xvii, 916 p. ISBN 8535209263. (pdf: Algoritmos - cap. 11)