Algoritmos de ordenação
Contato
- Jean Paulo Martins (jeanmartins utfpr edu br)
- Sala 105, Bloco S (UTFPR - Campus Pato Branco)
Conteúdo
Introdução
A ordenação de informação tem impacto relevante em diversos aspectos do nosso cotidiano. Considere, por exemplo, a ordem alfabética em que um dicionário é organizado, ou a ordem crescente (decrescente) em que os preços de um determinado produto são exibidos em uma compra online. Nessas situações, o fato da informação estar organizada (ordenada) de um modo consistente nos permite procurar por determinado item (uma palavra nos dicionários, um objeto de determinado valor na lista de compras) de forma muito mais simples.
Do ponto de vista computacional a ordenação de dados tem influência similar. Ao reorganizarmos a informação de forma consistente, diversas operações que poderiam ser feitas sobre o conteúdo armazenado podem, possivelmente, se tornar mais simples e eficientes.
Em princípio qualquer sequência de dados pode ser ordenada. Para isso, no entanto, é necessário que exista uma relação de ordem para o conjunto dos dados a serem ordenados. Sem perda de generalidade, consideraremos que cada item $i$ na sequência a ser ordenada possui uma chave $k_i\in \mathbb{D}$, tal que essas chaves pertençam a um domínio para o qual exista uma relação de ordem $R \subseteq \mathbb{D}\times \mathbb{D}$. Exemplos de relações de ordem totais mais comuns são: menor ou igual ($\leq$) e maior ou igual ($\geq$).
Ordenação de inteiros
Suponha uma sequência finita de números inteiros dispostos em uma ordem arbitrária, gerado de forma aleatória, por exemplo. Podemos representar essa sequência por:
Como o conjunto dos números inteiros $\mathbb{Z}$ é totalmente ordenado de acordo com a relação de ordem $\leq$, existe então uma reordenação dos elementos dessa sequência $\alpha : \mathbb{Z}\to\mathbb{Z}$, tal que:
O mesmo é verdade para a relação de ordem $\geq$, e portanto existe também uma reordenação $\beta : \mathbb{Z}\to\mathbb{Z}$
Transformar uma sequência de dados em ordem arbitrária em uma sequência ordenada é o objetivo dos algoritmos de ordenação que veremos a seguir.
O que são Algoritmos de ordenação?
Um algoritmo de ordenação é um procedimento que recebe como entrada uma sequência de dados, os quais assumiremos como números inteiros daqui em diante, e rearranja os items dessa sequência de modo que ao final eles estejam em uma determinada ordem: crescente, decrescente, por exemplo.
Algoritmos de Ordenação
Definidos os objetivos de um algoritmo de ordenação, é interessante iniciaremos a discussão nos questionando qual seria nossa estratégia para solucionar o problema da ordenação. Dada uma sequência numérica em um vetor int* v, qual seria sua intuição para um procedimento que reordenasse essa sequência de forma crescente?
Ao pensarmos um pouco sobre esse problema, são grandes as chances que tenhamos concluído algum dos algoritmos de ordenação que serão descritos a seguir.
Estratégias simples
Bubble sort
Dada uma sequência de entrada, a ordenação por trocas compara pares de itens $x_i$ e $x_{i+1}$ e os troca de posição caso $x_i>x_{i+1}$. Isso tem como efeito levar para posições posteriores aquele elemento que seja o maior.
if (x[i] > x[i+1])
swap(x, i, i+1); // Trocar os elementos nas posições i e i+1
Os gifs abaixo foram obtidos em https://imgur.com/gallery/iwTNP
O Bubble sort percorre do início ao fim do vetor várias vezes, efetuando trocas da forma acima. Na primeira passagem pelo vetor, o maior elemento é levado à posição final $x_{n}$, e, portanto, já estará na posição correta. A próxima iteração levará o segundo maior valor à posição anterior a final $x_{n-1}$ e assim sucessivamente, até que o primeiro elemento seja avaliado. Neste momento, o algoritmo precisa parar pois o vetor estará ordenado e nenhuma troca adicional ocorrerá.
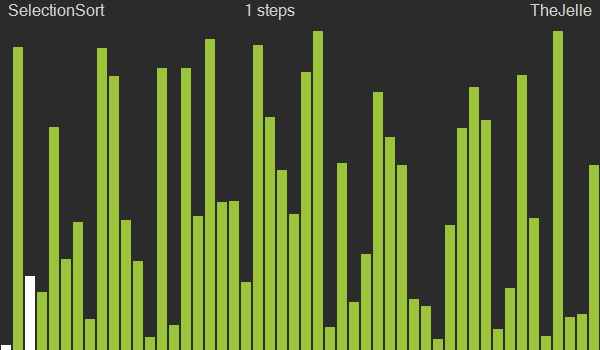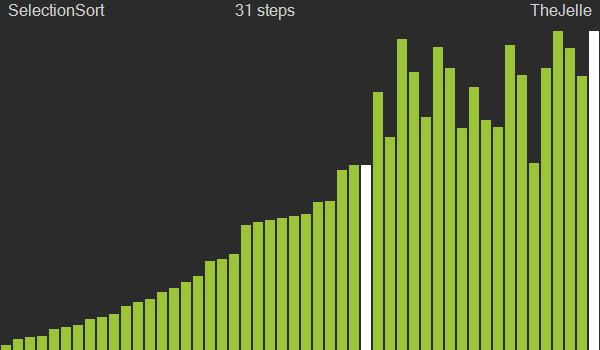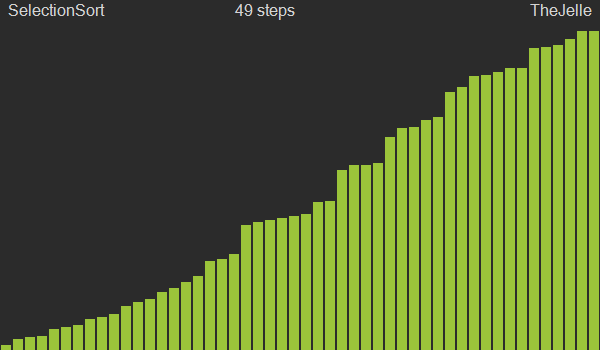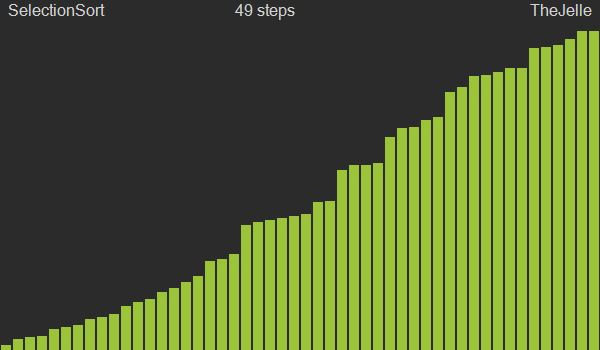
Selection sort
Dada uma sequência de entrada, a ordenação por seleção seleciona a cada passagem pelo vetor o menor/maior elemento e o coloca na posição inicial $x_1$ (ou final $x_n$). Na segunda iteração o menor elemento entre $x_2$ e $x_n$ será selecionado e colocado na posição $x_2$. Ou seja, a cada iteração, o algoritmo deixa um elemento a mais na posição correta.
// Trocar os elementos nas posições i e posição do menor elemento de i a n.
swap(x, i, min(x, i, n));
Insertion sort
Dada uma sequência de entrada, a ordenação por inserção percorre a sequência e para cada valor em uma determinada posição $i$, reinsere o valor $x_i$ na sua posição correta no momento. A posição correta $j$ para um elemento qualquer $x_i$ em um dado momento é aquela posição tal que $x_{j} \leq x_i \leq x_{j+1}$.
Estratégias recursivas
Quicksort
Consideremos uma sequência numérica qualquer de tamanho $n$, em ordem arbitrária.
Vamos analisar as propriedades produzidas pelo seguinte procedimento, o qual é mais simples que a ordenação em si.
Dado qualquer elemento desta sequência $x_p$, o qual chamaremos pivô, reordene a sequência de modo que $\forall x_i$ que preceda $x_p$, $x_i\leq x_p$. Em contrapartida, $\forall x_j$ que suceda $x_p$, $x_p \leq x_j$. Observe que não estamos exigindo que os elementos anteriores ou posteriores a $x_p$ estejam ordenados. No entanto, uma propriedade importante é evidente.
- Se todos antes de $x_p$ são menores ou iguais a ele e todos elementos depois são maiores ou iguais, então $x_p$ está na sua posição correta. Ou seja, na posição que ele ocuparia em uma sequência ordenada.
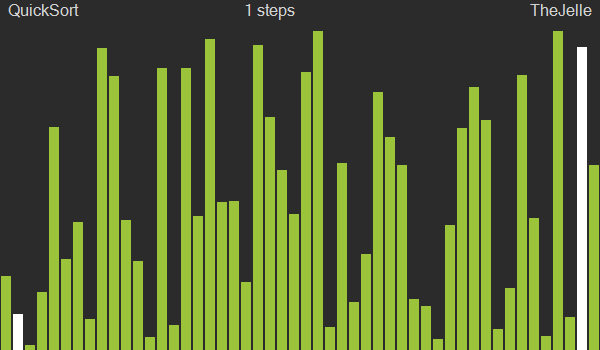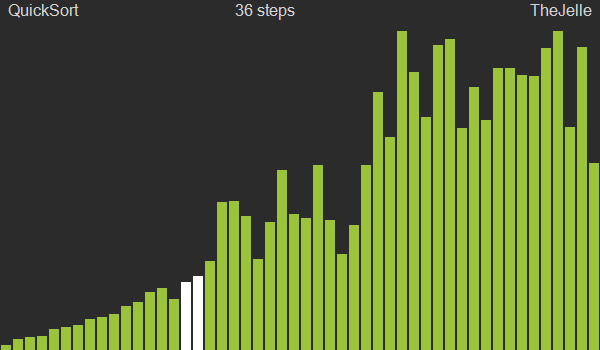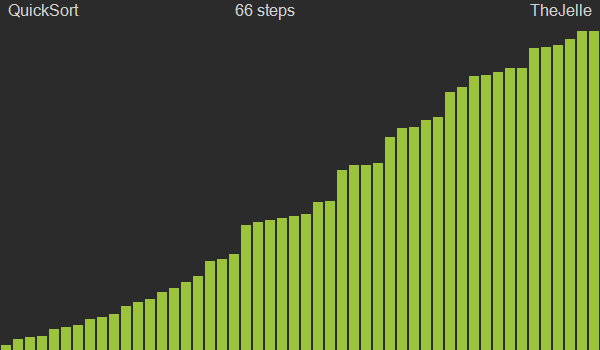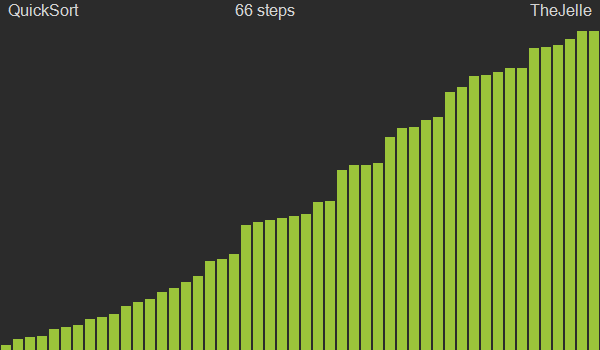
Por essa propriedade concluímos que $x_p$ não precisa mais ser comparado a nenhum outro elemento. Nos restando duas subpsequências a serem ordenadas. Aquela contendo os elementos anteriores e aquela contendo os elementos posteriores a $x_p$.
Podemos então repetir o mesmo procedimento em cada uma dessas subsequências, até que todos elementos tenham sido considerados como pivô e, portanto, colocados em suas devidas posições ordenadas.
O Algoritmo acima descrito é chamado, no contexto do Quicksort, de partition.
Partition
Dada uma sequência númerica em ordem arbitrária como entrada e um valor pivô $k$.
Partition irá produzir uma nova sequência, com o pivô numa posição $p$, de modo que $y_i \leq k$, $\forall i \leq p$ e $y_j \geq k$, $\forall j \geq p$.
Outra característica importante dessa nova sequência é que todos elementos $y_1,\dots,y_{p-1}$ são menores que aqueles em $y_{p+1},\dots,y_n$. Portanto, eles não precisam mais ser comparados. As comparações adicionais acontecerão internamente a cada uma das sequências apenas.