APS4 - Matrizes esparsas
Contato
- Jean Paulo Martins (jeanmartins utfpr edu br)
- Sala 105, Bloco S (UTFPR - Campus Pato Branco)
Conteúdo
Visão Geral
Objetivo
Implementar o algoritmo de multiplicação de matrizes.
- Utilizando tabelas hash como estruturas de dados para armazenar a matriz.
- Utilizando matrizes esparsas encadeadas como estruturas de dados para armazenar a matriz.
Critérios de avaliação
- Armazenamento da matriz esparsa em tabela hash.
- Armazenamento da matriz esparsa em estrutura encadeada.
- Multiplicação de matriz usando tabelas hash
- Multiplicação de matriz usando estruturas encadeadas.
Matrizes esparsas
Uma matriz $N\times M$ é uma estrutura de dados simples e comumente utilizada em situações nas quais existe uma relação entre um elemento e $M$ outros elementos. Todos elementos numa mesma linha estão relacionados por alguma propriedade que os fez serem armazenados em tais posições, essa propriedade depende da informação sendo armazenada. Consideremos a estrutura ilustrada abaixo.

Observamos pela numeração dos elementos que existem 13 nós. Percebemos também que além disso que alguns desses nós estão relacionados, ou seja, estão conectados por uma linha. Estruturas desse tipo são chamadas grafos, os elementos são chamados vértices e as conexões são chamadas arestas. Como representar uma estrutura desse tipo na memória do computador?
A primeira opção para representarmos um grafo como estruturas de dados é a utilização de uma matriz $N\times N$, onde $N=13$ é o número de vértices. Para cada aresta entre vértices $v_i$ e $v_j$, representada como $(v_i, v_j)$ um valor será inserido na posição $i,j$ da matriz. Na matriz abaixo, marcamos como $X$ todas as arestas no grafo acima.
- A primeira linha e primeira coluna servem apenas de referência, não existiriam na prática.
Usando este exemplo simples, é fácil percebermos que há um grande desperdício de memória ao utilizarmos essa estrutura de dados. Grande parte das conexões não existem no grafo que queremos representar, e portanto, a maioria das posições M[i][j] na matriz permanecerão inutilizadas.
Tabelas Hash
Como forma de economia de memória, podemos armazenar a matriz $M$ de outras forma. A primeira que discutiremos utiliza uma tabela hash como estrutura de dados subjacente. Assuma que tenhamos uma tabela hash com tratamento de colisões qualquer. Podemos definir que a informação a ser armazenada será uma estrutura, como um elemento da matriz M (Melem).
typedef struct {
int i,j;
Type valor;
} Melem;
Cada elemento desse tipo representa uma posição na matriz $M$, obviamente só armazenaríamos aqueles elementos representados por $X$, ou seja, aqueles que representem arestas no grafo original.
- Neste exemplo,
valoré até desnecessário, mas em outras situações é comum querermos armazenar algo na posição da matriz.
Neste tipo de situação, a existência, na tabela hash, de um elemento
Melem m = {10,9, 'X'};
Significaria a existência de uma aresta entre os vértices $v_{10}$ e $v_{9}$, ou seja $(v_{10}, v_{9})$.
Chaves únicas
Em uma tabela hash, os elementos armazenados precisam necessariamente possuir uma chave única que o distingua dos demais elementos. No contexto dos elementos de matriz (Melem) é possível utilizarmos os índices $i$ e $j$ para compor uma chave.
- Defina uma função que transforme $i$ e $j$ em uma chave única. Essa chave será utilizada como entrada da função hash.
Listas de Adjacências
Uma abordagem alternativa que é uma intermediária entre uma matriz comum e uma estrutura encadeada, são as chamadas listas de adjacências. Numa lista de adjacências, cria-se um vetor de L tamanho $N$, sendo que cada posição armazenará uma lista encadeada.
Diferentemente das tabelas hash, no entanto, temos total controle quanto a em qual lista inserir um determinado elemento. Como temos $N$ listas, a escolha óbvia é inserir um determinado elemento de matriz {i,j,valor} na lista lista da posição L[i]. A matriz $M$ descrita anteriormente seria então representada como
Onde por conveniência e melhor visualização representei nas listas apenas o indice $j$ ao invés do elemento de matriz completo (Melem).
Apesar da economia de memória que as listas de adjacências nos oferece, elas possuem um ponto fraco. As informações armazenadas nesse tipo de estrutura somente são facilmente acessadas percorrendo-se uma das linhas em $L$. Em diversas situações precisamos percorrer a matriz por coluna, uma operação que não é facilmente implementada em listas de adjacências.
Matrizes esparsas encadeadas
A implementação de matrizes esparsas por estruturas encadeadas é uma extensão da implementação em listas de adjacências. Neste caso, no entanto, se torna possível percorrer a matriz tanto em ordem definida por linha, quanto em ordem definida por coluna. Como isso é feito?
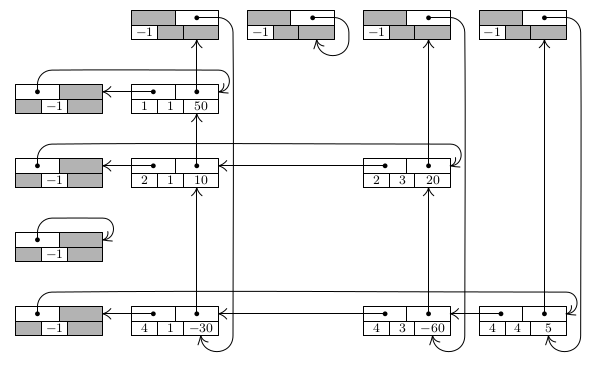
As matrizes esparsas encadeadas que trataremos aqui, consideram dois vetores: vetor linha, e vetor coluna, ambos são vetores de listas. Porém, diferentemente das listas que temos tratados até então, essas precisam de informações adicionais.
Considere que eu deseje percorrer uma linha $i$ da matriz esparsa encadeada. Dado um ponteiro para um nó $p$ da lista L[i], basta utilizarmos o campo next desse nó para acessarmos o próximo elemento na mesma linha.
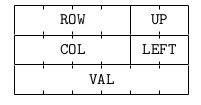
Por outro lado, se quisermos percorrer uma coluna $j$ da matriz esparsa encadeada, precisamos ter referência para os elementos abaixo e acima de um determinado elemento de matriz. Em resumo, cada nó dessas listas precisa armazenar pelo menos ponteiros para: abaixo e proximo, ou abaixo e anterior, ou acima e anterior etc; de modo que seja possível percorre a matriz tanto por linhas quanto por colunas. As figuras abaixo ilustram uma matriz esparsa encadeada com nós do tipo acima (UP) e anterior (LEFT).